向量检索(Vector Search)
向量检索是一种基于向量相似度的检索方法,在处理非结构化数据(如文本、图片、音频)时,特别适用于语义搜索、推荐系统和RAG(检索增强生成)。下面详细介绍向量检索相似评论的.
1.向量化文本数据
在进行相似评论搜索前,需要先将文本数据转换为|数值向量|(Embedding)。这通常由神经网络模型(如 OpenAI Embedding、BERT、FastText)完成。
- 输入: 文本评论,例如 "音质清晰,低音浑厚,性价比很高!"
- 输入: 一个高维向量,例如:
[0.123, -0.456, 0.789, ..., 0.032]
- 这些向量位于高维空间(通常 384 维、768 维甚至更高),相似的文本会在向量空间中靠得更近。
2.计算向量相似度
在向量数据库中存储的所有评论都被转换为向量,现在我们希望找到与查询最相似的评论。 最常见的相似度计算方法有:
(1)余弦相似度(Cosine Similarity)
衡量两个向量的夹角,值域为 [-1, 1],值越接近 1,表示越相似:
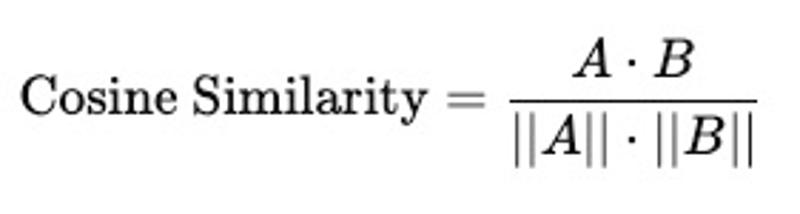
double cosineSimilarity(List<Double> vectorA, List<Double> vectorB) {
double dotProduct = 0.0;
double normA = 0.0;
double normB = 0.0;
for (int i = 0; i < vectorA.size(); i++) {
dotProduct += vectorA.get(i) * vectorB.get(i);
normA += Math.pow(vectorA.get(i), 2);
normB += Math.pow(vectorB.get(i), 2);
}
return dotProduct / (Math.sqrt(normA) * Math.sqrt(normB));
}
如果 cosineSimilarity = 0.98,说明两个评论语义上非常相似。
(2)欧几里得距离(Euclidean Distance)
 适用于高维度向量,但可能受数据规模影响较大。
适用于高维度向量,但可能受数据规模影响较大。
(3) 内积(Dot Product)
简单高效,常用于推荐系统,但受向量长度影响较大:
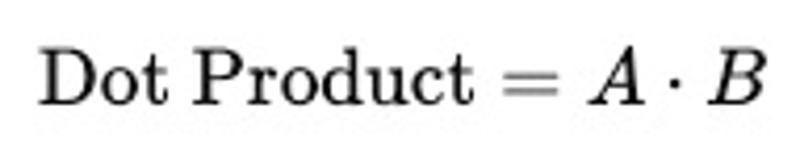
3.使用向量数据库进行近似最近邻搜索(ANN)
当评论数据量较大时,逐个计算相似度的方式效率低下,因此使用**近似最近邻搜索(Approximate Nearest Neighbors, ANN)**来提高检索效率。
3.1常见向量数据库
| 向量数据库 | 主要特点 |
|---|---|
| FAISS | Facebook 开源,内存优化,高速 ANN 计算 |
| Milvus | 企业级向量数据库,支持 GPU/分布式计算 |
| Weaviate | 适合大规模语义搜索,支持 GraphQL 查询 |
| Pinecone | 云原生向量数据库,无需维护 |
3.2 Milvus 示例
import io.milvus.param.dml.SearchParam;
import io.milvus.response.R;
import io.milvus.grpc.SearchResults;
public List<String> searchReviews(String query, int topK) {
// 1. 生成查询文本的嵌入向量
List<Double> queryVector = embeddingService.generateEmbeddings(List.of(query)).get(query);
// 2. 进行 ANN 搜索
SearchParam searchParam = SearchParam.newBuilder()
.withCollectionName("reviews_collection")
.withTopK(topK) // 取前 K 个最相似的
.withVectors(List.of(queryVector))
.withMetricType(MetricType.COSINE)
.build();
R<SearchResults> response = milvusClient.search(searchParam);
return response.getData().getFields("comment");
}
4.示例:查找相似评论
假设用户输入: "低音效果不错,但高音有点刺耳"
步骤:
- 该文本被转换为向量 query_vector。
- 使用 Milvus 或 FAISS 在已存向量数据库中检索。
- 计算余弦相似度,找到 Top-K 最接近的评论。
- 返回相似评论,例如:
[
{"id": 7, "comment": "低音不错,但高音略显刺耳,希望能优化。"},
{"id": 17, "comment": "低音不错,但音量最大时会有轻微破音。"},
{"id": 12, "comment": "高音清晰,低音饱满,但音量开大后会有失真。"}
]
用户得到语义最接近的评论,实现类似 AI 智能推荐。
5.向量检索 vs 传统关键词匹配
| 向量检索(ANN) | 传统关键词匹配 | |
|---|---|---|
| 匹配方式 | 语义级别匹配 | 关键词完全匹配 |
| 适用场景 | 含义相近但表达不同 | 关键词固定、搜索精准 |
| 示例 | “低音震撼”≈“低音强劲” | “低音震撼” ≠ “低音不错” |
| 优缺点 | 语义理解强,适合 NLP | 精准匹配,但不支持近义词 |
